A first look at Windows 10 prefetch files
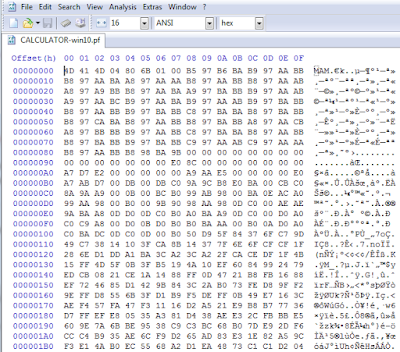
Windows 10 prefetch files (*.pf) show a different file format compared to previous ones. At first glance you'll spot no textual strings inside, and this was the initial reason that make me try to understand how they changed. quick&dirty journey I guess that neither you nor I will run into Windows 10 DFIR cases for a while. That's what I thought when Claudia Meda ( @KlodiaMaida ) contacted me, showing me a couple of Windows 10 prefetch files. She then provided me some interesting clues that tickled the curious george monkey in me. Officially I do not have spare time, since it's already allocated, so I illegally used the non-existent spare time of spare time: please don't betray me... so I hope you'll tolerate any shortcuts in my quick&dirty journey into the entrails of windows (disgusting, isn't it?). first lead First, what a nude prefetch file has to say? Check the first bytes in the next figure, which shows a prefetch file...