A first look at Windows 10 prefetch files
Windows 10 prefetch files (*.pf) show a different file format compared to previous ones. At first glance you'll spot no textual strings inside, and this was the initial reason that make me try to understand how they changed.
quick&dirty journey
I guess that neither you nor I will run into Windows 10 DFIR cases for a while. That's what I thought when Claudia Meda (@KlodiaMaida) contacted me, showing me a couple of Windows 10 prefetch files. She then provided me some interesting clues that tickled the curious george monkey in me. Officially I do not have spare time, since it's already allocated, so I illegally used the non-existent spare time of spare time: please don't betray me... so I hope you'll tolerate any shortcuts in my quick&dirty journey into the entrails of windows (disgusting, isn't it?).
first lead
First, what a nude prefetch file has to say? Check the first bytes in the next figure, which shows a prefetch file for calc... sorry, now it's calculator (sad, I'll miss you dear calc!). They should remind you some other "prefetch folder" related file: can't you find your memo?
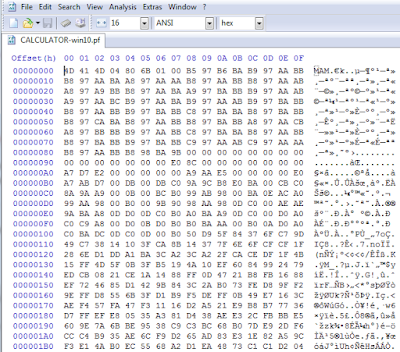
All kidding aside, what the MAM signature recalls is also used by the SuperFetch file format, which on Windows 7 exhibits the very similar MEMO / MEM0 signature. A great old (gosh, 2011!) post addressing the SuperFetch file format (and so MEM[0|O] format) is "Windows SuperFetch file format – partial specification" by ReWolf, a worth reading. From there, you can get that the MEM files are, in the first instance, compressed containers and that the Windows API in charge to decompress them is RtlDecompressBuffer.

When applied to our MAM case, in the end you get three bytes with the magic signature 0x4d4d41, one byte that identifies the compression algorithm used and, eventually, the presence of a checksum: the next 4 bytes are the uncompressed size of the original buffer, then if checksum is in place, you'll get 4 more bytespreceding after [errata 22.06.2015] the uncompressed size that contain the checksum. The remaining data is what must be decompressed with RtlDecompressBufferEx. Which algorithm in used?
The followings are the compression package types and procedures as they are in ntifs.h.
//
// Compression package types and procedures.
//
#define COMPRESSION_FORMAT_NONE (0x0000) // winnt
#define COMPRESSION_FORMAT_DEFAULT (0x0001) // winnt
#define COMPRESSION_FORMAT_LZNT1 (0x0002) // winnt
#define COMPRESSION_FORMAT_XPRESS (0x0003) // winnt
#define COMPRESSION_FORMAT_XPRESS_HUFF (0x0004) // winnt
#define COMPRESSION_ENGINE_STANDARD (0x0000) // winnt
#define COMPRESSION_ENGINE_MAXIMUM (0x0100) // winnt
#define COMPRESSION_ENGINE_HIBER (0x0200) // winnt
So considering that the MAM signature usually is followed by 0x4 (or 0x84), the algorithm is COMPRESSION_FORMAT_XPRESS_HUFF.
In the end we get that starting from Windows 10, Prefetch and SuperFetch files are compressed with the XPRESS HUFFMAN algorithm, actually a.k.a. the MAM format. Which is not new: Windows 8.1 uses it to compress SuperFetch files, but not Prefetch files. Moreover from what I see checksum is present only for SuperFetch files and never for Prefetch files.

All kidding aside, what the MAM signature recalls is also used by the SuperFetch file format, which on Windows 7 exhibits the very similar MEMO / MEM0 signature. A great old (gosh, 2011!) post addressing the SuperFetch file format (and so MEM[0|O] format) is "Windows SuperFetch file format – partial specification" by ReWolf, a worth reading. From there, you can get that the MEM files are, in the first instance, compressed containers and that the Windows API in charge to decompress them is RtlDecompressBuffer.
an actionable lead
I launched windbg inside a Windows 10 virtualized guest (Pro Insider Preview 10.0.10074) and I put a couple of bp on RtlDecompressBuffer and RtlDecompressBufferEx functions: the target process is the SuperFetch process, the svchosted sysmain.dll. To be short, I landed on the moon, which in the case is the sysmain!SmDecompressBuffer method: in the next picture you can see some green boxes (I signed following the decompression branch) and some yellow boxes (checksum check, more on this later).

The routine core is represented in the next picture, where you can (could, if I correctly re-sized the image) easily spot the call to the target method RtlDecompressBufferEx.

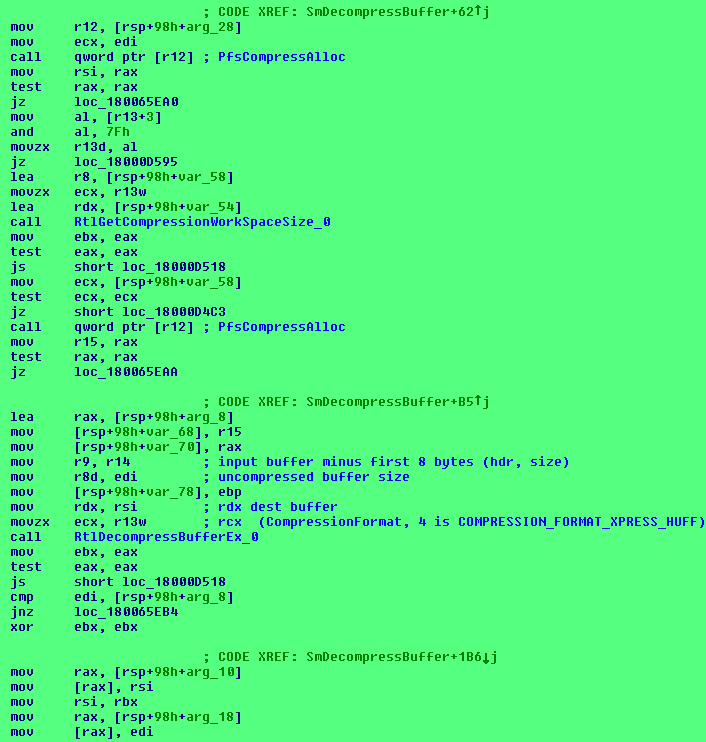
When applied to our MAM case, in the end you get three bytes with the magic signature 0x4d4d41, one byte that identifies the compression algorithm used and, eventually, the presence of a checksum: the next 4 bytes are the uncompressed size of the original buffer, then if checksum is in place, you'll get 4 more bytes
The followings are the compression package types and procedures as they are in ntifs.h.
//
// Compression package types and procedures.
//
#define COMPRESSION_FORMAT_NONE (0x0000) // winnt
#define COMPRESSION_FORMAT_DEFAULT (0x0001) // winnt
#define COMPRESSION_FORMAT_LZNT1 (0x0002) // winnt
#define COMPRESSION_FORMAT_XPRESS (0x0003) // winnt
#define COMPRESSION_FORMAT_XPRESS_HUFF (0x0004) // winnt
#define COMPRESSION_ENGINE_STANDARD (0x0000) // winnt
#define COMPRESSION_ENGINE_MAXIMUM (0x0100) // winnt
#define COMPRESSION_ENGINE_HIBER (0x0200) // winnt
decompress-ing
To replicate and double checking that findings, I created a small Python Windows native script: with native I pinpoint that you can't use on other OSes different from Windows, since it uses native api calls. Moreover you need Windows 8.1 at least, since the RtlDecompressBufferEx was introduced starting from that OS version. You could use the script to decompress prefetch files, if in need: but you'll get a better solutions at the end of the post. I tweeted about this script some days ago, pointing to a gist I made and that you can find at w10pfdecomp.py.
checksum-ing
In the first instance I ignored the checksum assembly branch, but then I realized that SuperFetch Windows 10 files show the same MAM signature: by applying the previous script, decompression fails. Previously I introduced the fact that a checksum could be present in the prefetch file, when in the third byte (algorithm) you get the most significant bit set: in those cases you see 0x84 as the byte value.
Reconsidering the checksum branch, here is it what happens: the (prefetch|superfetch) file will have 4 more bytes set to the calculated checksum, those bytes stored after the decompresion size (so, bytes 8-11, starting to count from 0): that bytes must be skipped during the decompression phase.
The checksum is a simple CRC32, calculated on the whole file, zeroing out the current file checksum: you can then realize why in the dis-assembly RtlComputeCrc32 is called three times. I'll updated my Python script to consider that checksum, both on the gist and on the hotoloti github repository.
Reconsidering the checksum branch, here is it what happens: the (prefetch|superfetch) file will have 4 more bytes set to the calculated checksum, those bytes stored after the decompresion size (so, bytes 8-11, starting to count from 0): that bytes must be skipped during the decompression phase.
The checksum is a simple CRC32, calculated on the whole file, zeroing out the current file checksum: you can then realize why in the dis-assembly RtlComputeCrc32 is called three times. I'll updated my Python script to consider that checksum, both on the gist and on the hotoloti github repository.
yaJUl
No, I'm not drunk. yajul (it sounds nice) means Yet Another Joachim Uber Library. Joachim Metz published and currently maintains, among many others, the "Windows Prefetch File (PF) format" document, where he describes the various formats those file use: if you couple it with his "Windows SuperFetch database format", you'll get all the intimate details of Prefetch and SuperFetch files, compression containers included.
Moreover, his libssca (Prefetch files) and libagdb (SuperFetch files) libraries, with the help of libfwnt, are able to correctly handle the decompression and parsing of MAM compression containers (well, the libraries handles all the variants), and that is damned cool!
I want to personally thank Joachim for his prompt support when I reached him with my findings: among other things I got very good suggestions and observations on my short research. I want to share with you an interesting link he provided to me, link to a work made by Jeff Bush on Microsoft Compression Formats.
Moreover, his libssca (Prefetch files) and libagdb (SuperFetch files) libraries, with the help of libfwnt, are able to correctly handle the decompression and parsing of MAM compression containers (well, the libraries handles all the variants), and that is damned cool!
I want to personally thank Joachim for his prompt support when I reached him with my findings: among other things I got very good suggestions and observations on my short research. I want to share with you an interesting link he provided to me, link to a work made by Jeff Bush on Microsoft Compression Formats.
conclusions
In the end we get that starting from Windows 10, Prefetch and SuperFetch files are compressed with the XPRESS HUFFMAN algorithm, actually a.k.a. the MAM format. Which is not new: Windows 8.1 uses it to compress SuperFetch files, but not Prefetch files. Moreover from what I see checksum is present only for SuperFetch files and never for Prefetch files.
It remains unclear why Prefetch and SuperFetch files are compressed. Usually compression means space saving (IO reduction?) and computational effort, but it could mean obfuscation too: if you have any clue, I'd be happy to get it.
Anyway with the excellent work made by Joachim we'll be able to understand and to handle those file without any problem. Last but not least, his work his Open Source: not bad, especially in the DFIR world, isn't it?
If you'd need my Python script you can download it from hotoloti or from the gist.
Anyway with the excellent work made by Joachim we'll be able to understand and to handle those file without any problem. Last but not least, his work his Open Source: not bad, especially in the DFIR world, isn't it?
If you'd need my Python script you can download it from hotoloti or from the gist.


Comments
Post a Comment